브라우저 PDF 처리와 WebAssembly: 업로드 없이 가능한 이유
2026-04-27 · 12 min read · onnova
PDF 도구를 엽니다. 파일을 끌어다 놓습니다. 진행 막대가 움직입니다.
예전 기준은 대체로 이랬습니다. 파일이 어딘가의 서버로 올라가고, 서버에서 처리된 뒤, 다시 다운로드됩니다.
그게 왜 기본값이어야 할까요?
브라우저 PDF 처리와 WebAssembly가 바꾼 건 이 지점입니다. PDF가 내 기기 안에 남아 있고, 브라우저가 그 자리에서 작업할 수 있습니다. 서버 대기열도, 수상한 업로드 단계도, "나중에 삭제합니다" 같은 약속도 먼저 믿을 필요가 줄어듭니다.

서버 처리가 기본값이 된 이유
서버 방식이 처음부터 말이 안 됐던 건 아닙니다.
PDF는 단순한 종이 이미지가 아닙니다. 폰트, 이미지, 주석, 양식, 압축 스트림, 메타데이터, 암호화, 페이지 트리까지 들어갑니다. 오래된 규격의 흔적도 꽤 남아 있습니다. 제대로 읽고 다시 쓰려면 만만한 작업이 아닙니다.
예전 브라우저는 이 작업에 잘 맞지 않았습니다. JavaScript는 지금보다 느렸고, 메모리 여유도 작았습니다. 무거운 작업을 돌리면 페이지가 멈춘 것처럼 보이기도 했습니다. 방문자마다 큰 문서 처리 라이브러리를 내려보내는 것도 부담이었습니다.
그래서 업계는 쉬운 길을 택했습니다.
파일을 올립니다. 서버에서 처리합니다. 결과를 내려받습니다.
서비스 입장에서는 편합니다. 하지만 파일을 가진 사람 입장에서는 질문이 하나 생깁니다. 업로드된 뒤 내 PDF가 정확히 어디를 지나갔나요?
정말 빨리 지웠을 수도 있습니다. 로그가 남았을 수도 있습니다. 임시 저장소, CDN 캐시, 오류 리포트, 백업 시스템이 파일 일부를 봤을 수도 있습니다.
모든 게 괜찮을 수도 있습니다.
그래도 신뢰해야 하는 범위는 커졌습니다.
WebAssembly는 로컬 처리를 현실적으로 만들었습니다
WebAssembly는 프라이버시 주문이 아닙니다. 이 단어가 붙었다고 자동으로 안전해지는 건 아닙니다.
WebAssembly는 컴파일된 코드를 브라우저 안에서 빠르게 실행하게 해주는 방식입니다. 이게 중요한 이유는 성숙한 문서 처리 코드가 JavaScript에서만 태어난 것이 아니기 때문입니다. C, C++, Rust 같은 생태계에는 오래전부터 파일 파싱과 저수준 처리에 강한 코드가 있었습니다.
WebAssembly 덕분에 그런 작업 일부를 업로드 서버 뒤가 아니라 브라우저 안으로 가져올 수 있습니다.
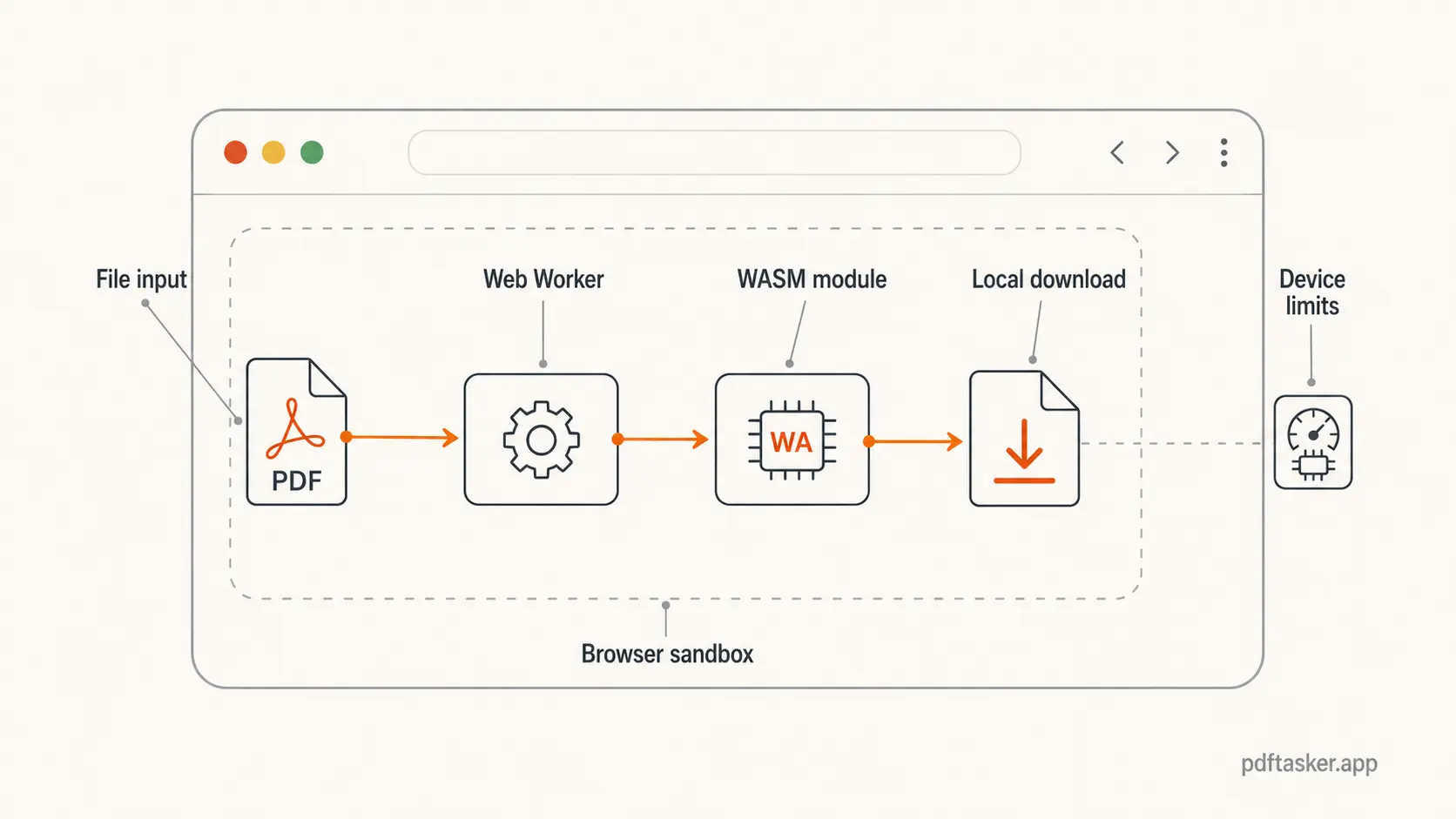
브라우저에는 여전히 경계가 있습니다. 코드는 브라우저 sandbox 안에서 실행됩니다. 사용자가 선택한 파일은 읽을 수 있습니다. 사용자가 선택했으니까요. 대신 하드디스크를 마음대로 뒤지는 식의 동작은 할 수 없습니다. 처리 결과는 Blob으로 만들어지고, 사용자는 그 파일을 바로 내려받습니다.
쓸모 있는 부분은 여기입니다.
꼼수 없습니다. 파일이 있던 자리에서 작업이 끝납니다.
Web Worker도 중요합니다. 무거운 PDF 작업을 UI thread에서 그대로 돌리면 화면이 멈춘 것처럼 보일 수 있습니다. Worker는 작업을 옆으로 빼 줍니다. 그래서 앱은 진행률, 오류, 취소 상태를 보여주면서 문서 작업을 계속할 수 있습니다.
PDFTasker가 택한 구조도 이쪽입니다. 정적 페이지가 로드되고, PDF 작업은 브라우저 쪽 Worker와 client-side library가 맡습니다. 결과 파일은 로컬에서 만들어져 다운로드됩니다.
"일단 올리고 나중에 믿어주세요"보다 단순한 약속입니다.
브라우저 전용이 만능이라는 뜻은 아닙니다
로컬 처리에도 한계가 있습니다. 이걸 숨기면 그때부터 마케팅 문구가 됩니다.
작업은 결국 사용자의 기기에서 돌아갑니다. 5MB 양식 PDF와 400MB 스캔 문서는 같은 일이 아닙니다. 브라우저 메모리, CPU, 파일 구조, 라이브러리 지원 범위가 모두 영향을 줍니다.
PDF 압축도 버튼 하나처럼 보이지만 실제로는 여러 결정의 묶음입니다. 이미지 해상도를 낮출지, 쓰지 않는 객체를 정리할지, 스트림을 다시 쓸지, 어느 정도의 품질 손실을 받아들일지 판단해야 합니다. 어떤 파일은 잘 줄어듭니다. 어떤 파일은 거의 줄지 않습니다.
그래서 제대로 된 no-upload 도구라면 무엇을 할 수 있고, 무엇은 어렵다고 말해야 합니다.
프라이버시도 마찬가지입니다. 어떤 도구가 WebAssembly를 쓰면서도 파일을 업로드할 수 있습니다. "browser-based"라고 말하면서 예상보다 많은 데이터를 외부로 보낼 수도 있습니다.
그러니 단어만 보지 마세요. 파일 경로를 보세요.
필요하면 DevTools를 열고 Network 탭을 보세요. 테스트용 PDF를 넣은 뒤 큰 outbound request가 생기는지 확인합니다. 문서 업로드 없이 결과가 만들어지는지도 봅니다.
푸터에 적힌 부드러운 문장보다 이쪽이 낫습니다.
no-upload PDF 도구를 확인하는 기준
브라우저 엔진을 감사할 필요까지는 없습니다.
실무 기준은 이 정도면 충분합니다.
-
파일 요청이 밖으로 나가는지 봅니다. no-upload 흐름이라면 PDF 자체가 문서 처리 endpoint로 전송되지 않아야 합니다.
-
페이지 로드 뒤에도 작업이 되는지 봅니다. 로컬 도구는 앱 코드가 로드된 뒤에도 작업을 이어갈 수 있습니다. 매번 새 서버 왕복이 필요하다면 이유가 있어야 합니다.
-
Worker 기반 동작이 보이는지 봅니다. 진행률, 취소, 반응형 UI는 무거운 작업을 main thread에 모두 얹지 않았다는 신호일 수 있습니다.
-
한계를 말하는지 봅니다. 좋은 로컬 도구는 파일 크기와 브라우저 메모리 한계를 인정합니다. 애매한 약속은 기능이 아닙니다.
-
작업에 맞는 도구를 고릅니다. 공유 전 파일을 줄여야 한다면 브라우저 우선 PDF 압축 도구를 써볼 수 있습니다. 민감한 파일이라면 최종본을 보내기 전에 메타데이터 정리도 확인하는 편이 낫습니다.
PDFTasker가 일부러 지루한 구조를 택한 이유도 여기에 있습니다. 서비스는 브라우저 쪽 처리, 정적 페이지, Worker를 중심으로 만들어져 있습니다. 서버 문서 대기열을 기본값으로 두지 않습니다.
멋있어 보이려고 그런 게 아닙니다.
"업로드한 뒤 내 파일이 어디 갔지?"라는 질문을 줄이기 위해서입니다.
지루한 구조가 핵심입니다.
좋은 브라우저 기반 PDF 도구는 요란할 필요가 없습니다.
파일을 고릅니다. 브라우저가 읽습니다. Worker가 무거운 일을 맡습니다. 로컬 결과물이 만들어집니다. 내려받습니다.
그게 전부입니다.
파일이 기기를 떠날 필요가 없다면 떠나지 않는 편이 맞습니다. 업로드가 필요하다면 도구는 그렇게 말해야 합니다.
압축, 병합, 분할, 서명, 보호, 메타데이터 정리 같은 일상적인 PDF 작업은 이제 예전보다 더 많이 브라우저가 감당할 수 있습니다.
그 기준을 쓰면 됩니다. 신뢰 범위를 작게 두세요.
PDFTasker
압축