"1 घंटे बाद delete" privacy promise नहीं है
2026-04-25 · 6 min read · onnova
"Site कहती है कि मेरी file एक घंटे बाद delete हो जाएगी. क्या इतना काफी है?"
यह सवाल तब आता है जब कोई tax form, contract, school document, या ID scan किसी free PDF tool में डालना पड़ता है.
छोटा जवाब: अक्सर नहीं.
समस्या यह नहीं है कि timed deletion झूठ है. वह सच हो सकता है. समस्या यह है कि वह उस सवाल से छोटा जवाब देता है जो user असल में पूछ रहा होता है.
वह retention का जवाब देता है.
Exposure का नहीं.

वादा risky हिस्से के बाद शुरू होता है
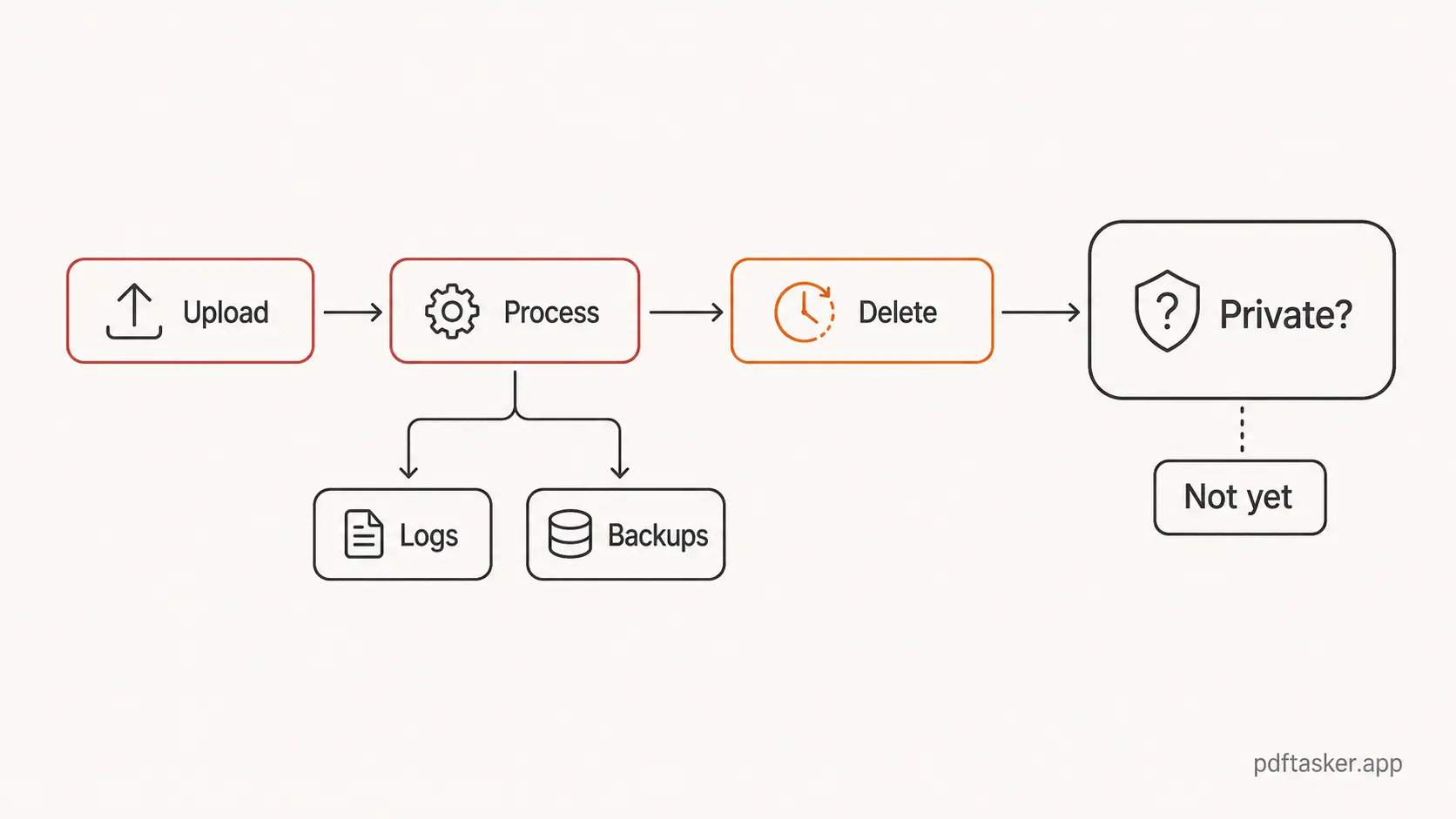
Upload-first PDF tools का रास्ता आसान है. आप file चुनते हैं. Browser उसे server पर भेजता है. Server काम करता है. आप result download करते हैं. फिर service किसी तय समय के बाद file delete कर सकती है.
वह आखिरी step बेकार नहीं है. छोटा retention window हमेशा file को हमेशा रखने से बेहतर है. इस पर बहस नहीं.
लेकिन यह privacy के बराबर नहीं है.
File जैसे ही server तक पहुंचती है, trust surface बड़ा हो जाता है. Main copy कह सकती है कि file एक घंटे बाद delete हो जाती है, लेकिन file पहले ही request handling, temporary storage, processing queues, logs, backups, monitoring, error reports, या ऐसी infrastructure से गुजर चुकी हो सकती है जिसे आप कभी नहीं देखते. अच्छी service इन paths को कम कर सकती है. धुंधला वादा यह साबित नहीं करता कि उसने ऐसा किया.
"बाद में delete" और "कभी upload नहीं" एक ही claim नहीं हैं.
यह फर्क इसलिए मायने रखता है क्योंकि बहुत से users इस line को भावनात्मक तरीके से पढ़ते हैं. उन्हें "1 hour" दिखता है और वे "private" सुनते हैं. System का मतलब ज्यादा छोटा होता है: "हम इस period के बाद working file retain नहीं करना चाहते."
ये दोनों sentence एक जैसे नहीं हैं.
One-hour delete line में तीन patterns छिपे होते हैं
Online PDF tools के आसपास privacy confusion अक्सर एक जैसा होता है. Marketing copy file की life के अंत की बात करती है. User की असली चिंता शुरुआत को लेकर होती है.
Pattern 1. Retention को privacy समझ लिया जाता है
Retention का मतलब है कि service किसी चीज़ को कितनी देर रखती है.
Privacy का मतलब है कि शुरुआत में किसे access मिलता है.
दोनों जुड़े हैं, लेकिन एक-दूसरे की जगह नहीं ले सकते. File जल्दी delete हो सकती है और फिर भी remote system से गुजर चुकी हो सकती है. File थोड़ी देर process हो सकती है और फिर भी personal names, invoice numbers, signatures, metadata, या document structure आपके device के बाहर की infrastructure तक पहुंच सकते हैं.
इसीलिए "1 घंटे बाद delete" असल से ज्यादा comforting लग सकता है. यह कठिन हिस्से को timer में बदल देता है. Timer कठिन हिस्सा नहीं है.
कठिन हिस्सा यह है कि upload जरूरी था या नहीं.
Pattern 2. "Secure transfer" पूरी कहानी बन जाता है
एक और common line है encryption in transit. यह अच्छा है. यह basic plumbing भी है.
HTTPS file को आपके browser और server के बीच move करते समय protect करता है. इसका मतलब यह नहीं कि server को file कभी मिली ही नहीं. यह processing के दौरान क्या होता है, यह नहीं बताता. यह भी नहीं बताता कि कोई copy queue, cache, debug path, या support workflow में जाती है या नहीं.
इसलिए useful question यह नहीं है कि "pipe encrypted था?"
होना ही चाहिए.
बेहतर सवाल है: file को उस pipe में जाना ही क्यों पड़ा?
Pattern 3. Automatic deletion architecture को छिपा देती है
Automatic deletion operationally साफ सुनाई देता है. कई systems में शायद ऐसा होता भी है. Job चलती है. Temporary files गायब होती हैं. Product team policy और timer दिखा सकती है.
लेकिन architecture फिर भी मायने रखती है.
अगर काम के लिए server चाहिए, तो user को उस server-side process पर भरोसा करना पड़ता है. अगर वही काम browser के अंदर हो सकता है, तो user उस extra trust step से बच सकता है. फर्क यहीं है.
एक model कहता है, "हम पर भरोसा करें, हम file बाद में हटा देंगे."
दूसरा कहता है, "इस task के लिए हमें file अपने server पर चाहिए ही नहीं."
ये copy की अलग lines नहीं हैं. ये अलग operating models हैं.

छोटा trust surface कैसा दिखता है
बेहतर privacy model ज्यादा ऊंची आवाज वाला नहीं होता. वह छोटा होता है.
Everyday PDF work के लिए browser-first product app load कर सकता है, आपको file चुनने दे सकता है, bytes को Web Worker में दे सकता है, operation local चला सकता है, और result download के रूप में लौटा सकता है. Server website host कर सकता है, बिना वह जगह बने जहां आपका document process होता है.
PDFTasker इसी design के आसपास बना है: static pages, browser-side processing, Web Workers, और local downloads. Wider product context About page पर है, लेकिन जरूरी बात सरल है. Document work आपके device पर होना चाहिए, हमारे चलाए हुए document queue में नहीं.
इसका मतलब यह नहीं कि हर file अपने आप risk-free हो जाती है. आपका browser अभी भी मायने रखता है. आपका device भी. Download के बाद जो document आप share करते हैं, वह भी. अगर PDF में author names, revision history, embedded metadata, या दूसरे traces हैं, तो भेजने से पहले उन्हें साफ करना चाहिए.
यहीं local PDF metadata cleanup step काम आता है. यह outgoing document आपके बारे में क्या बताता है, उसे कम करता है, before anyone else receives it.
अगर document इतना sensitive है कि access control चाहिए, तो share करने से पहले PDF को password से protect करना भी काम आ सकता है. Password protection अपने आप privacy story नहीं है. यह बस एक practical layer है.
Pattern वही है: छोटे claims, छोटा trust surface, कम magic words.
Lawyer बने बिना privacy copy कैसे पढ़ें
हर छोटे PDF task के लिए security audit की जरूरत नहीं है. बस कुछ sharper questions काफी हैं.
- क्या tool असली काम दिखाने से पहले file upload करता है?
- क्या privacy copy बताती है कि processing कहां होती है, या सिर्फ delete कब होता है?
- क्या product browser-side work, local processing, या Web Workers के बारे में concrete बात करता है?
- क्या वह narrow claims करता है, या "secure" जैसे बड़े शब्दों से चाहता है कि आप पढ़ना बंद कर दें?
आखिरी point अक्सर tell होता है.
अच्छी privacy copy आम तौर पर boring होती है. वह बताती है कि क्या होता है और क्या नहीं. वह आपसे deletion timer देखकर architecture guess करने को नहीं कहती.
PDFTasker
Metadata हटाएँ
अगर आप PDF भेजने से पहले clean कर रहे हैं, तो उस हिस्से से शुरू करें जिसे आप control करते हैं. Metadata local रूप से remove करें. कम share करें. कम infrastructure पर भरोसा करें. यह dramatic नहीं है.
यही वह हिस्सा है जो सच में मदद करता है.