Browser में PDF कैसे process होता है: WebAssembly की सीधी बात
2026-04-27 · 6 min read · onnova
आप कोई PDF tool खोलते हैं। File drag करते हैं। Progress bar चलने लगती है।
पुरानी धारणा सीधी थी: file किसी server पर गई होगी, वहाँ process हुई होगी, फिर download के रूप में वापस आई होगी।
लेकिन यह default क्यों होना चाहिए?
Browser based PDF tool WebAssembly के साथ इस सवाल का जवाब बदलता है। PDF आपके device पर रह सकती है, और browser वहीं काम कर सकता है। Server queue नहीं। छिपा हुआ upload step नहीं। पहले से यह भरोसा करने की ज़रूरत कम कि "हम बाद में delete कर देंगे।"

Server default इसलिए बना क्योंकि browser पहले छोटे थे
Server वाला तरीका बिना वजह लोकप्रिय नहीं हुआ।
PDF सिर्फ page की तस्वीर नहीं है। उसमें fonts, images, annotations, forms, compression streams, metadata, encryption और page tree जैसी चीज़ें हो सकती हैं। कुछ पुराने format quirks भी साथ चलते हैं। इसे ठीक से पढ़ना और फिर से लिखना हल्का काम नहीं है।
पुराने browsers इस काम के लिए अच्छे नहीं थे। JavaScript धीमा था। Memory कम थी। Heavy work page को freeze जैसा बना सकता था। हर visitor को बड़ी document-processing library भेजना भी अजीब था।
इसलिए industry ने आसान रास्ता चुना।
File upload करो। Server process करे। Result वापस download करो।
Service के लिए यह आसान है। File वाले व्यक्ति के लिए नहीं। जैसे ही PDF device छोड़ती है, एक नया सवाल आ जाता है: upload के बाद file कहाँ-कहाँ गई?
शायद service ने जल्दी delete कर दिया। शायद metadata log हुआ। शायद temporary worker, storage bucket, CDN cache, crash report या backup system ने file का हिस्सा देखा।
हो सकता है सब ठीक हो।
फिर भी भरोसे का दायरा बड़ा हो गया।
WebAssembly ने local processing को व्यावहारिक बनाया
WebAssembly कोई privacy जादू नहीं है। नाम लग जाने से website अपने-आप safe नहीं हो जाती।
WebAssembly compiled code को browser के अंदर तेज़ चलाने का तरीका है। यह इसलिए काम का है क्योंकि mature document tooling सिर्फ JavaScript में पैदा नहीं हुई। C, C++, Rust जैसे ecosystems में low-level file parsing का लंबा इतिहास है।
WebAssembly की वजह से ऐसे काम का ज्यादा हिस्सा upload endpoint के पीछे नहीं, browser के अंदर चल सकता है।
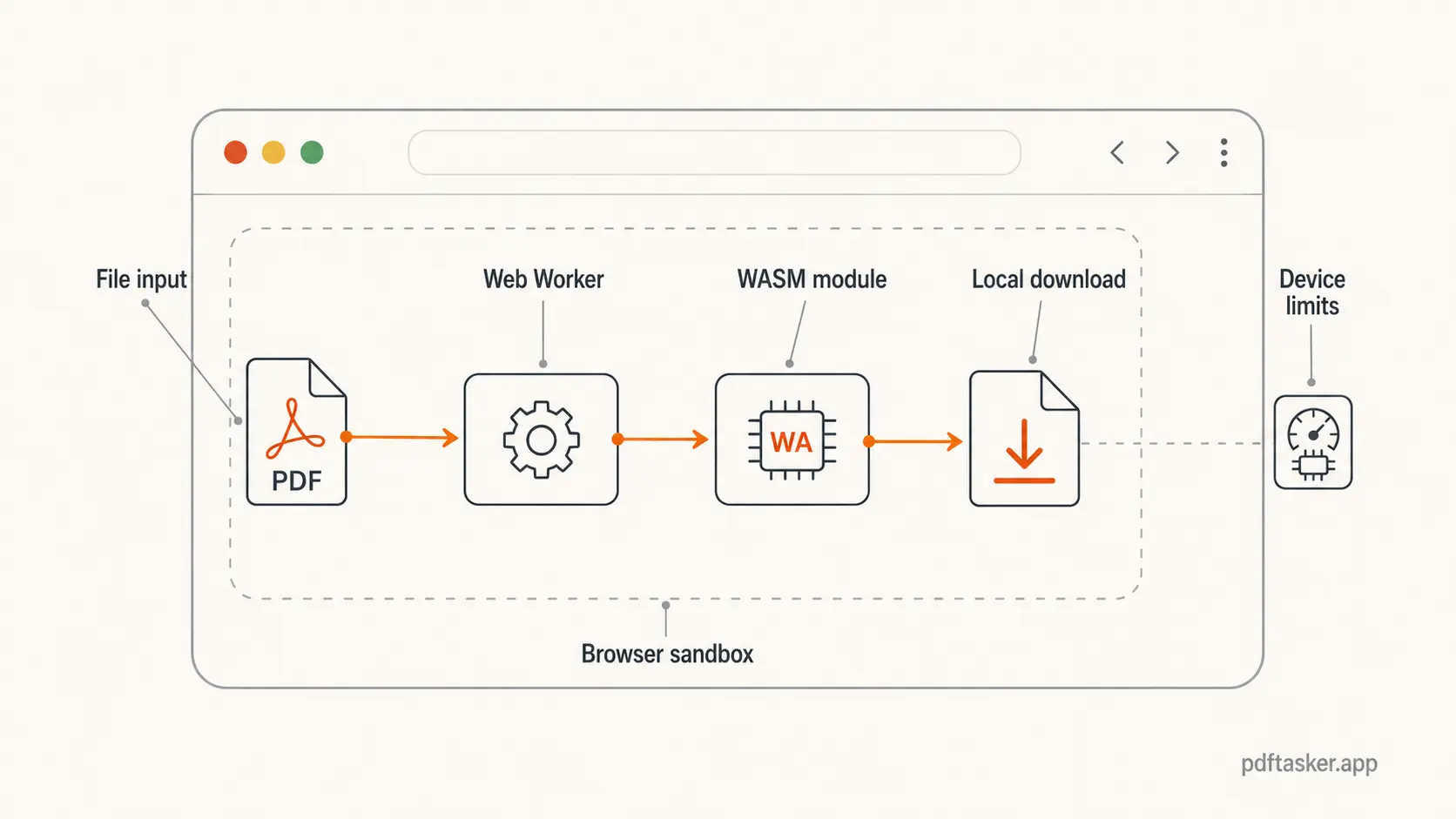
Browser की अपनी सीमाएँ रहती हैं। Code browser sandbox में चलता है। वह आपकी चुनी हुई file पढ़ सकता है, क्योंकि आपने उसे चुना है। वह आपके disk में ऐसे ही घूम नहीं सकता। Result Blob के रूप में बन सकता है और आप उसे download कर सकते हैं।
यही उपयोगी हिस्सा है।
No tricks. काम वहीं होता है जहाँ file पहले से है।
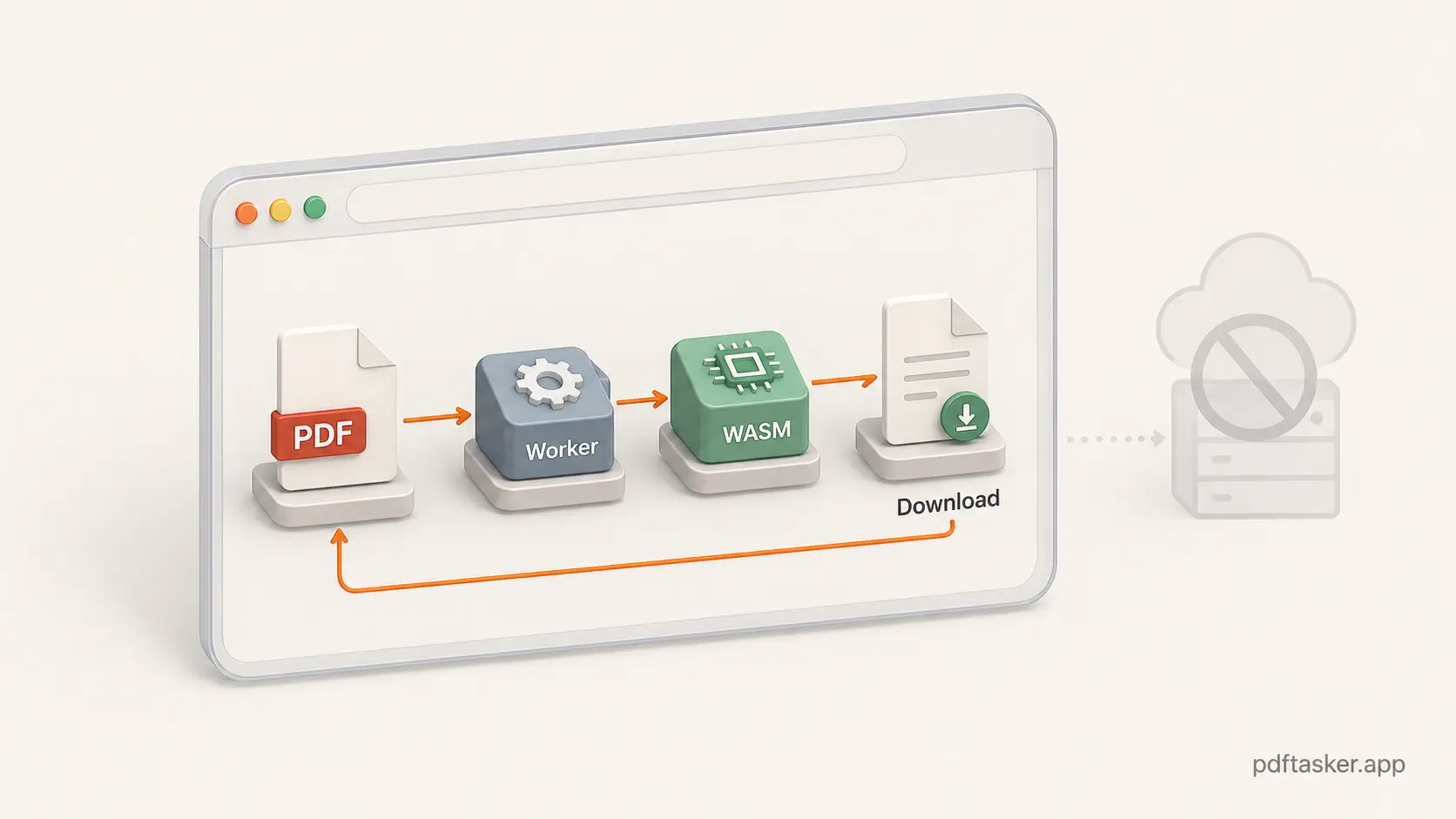
Web Workers दूसरा जरूरी हिस्सा हैं। Heavy PDF work को main UI thread पर डाल देंगे तो page अटका हुआ लगेगा। Worker processing को side में रखता है, ताकि app progress, error और cancel state दिखाती रहे।
PDFTasker इसी browser-first shape पर बना है। Static web page load होता है। PDF work browser-side workers और client-side libraries को जाता है। Output locally बनता है और download हो जाता है।
"पहले upload करो, बाद में भरोसा करो" से यह बात छोटी और साफ़ है।
Browser-only का मतलब सब कुछ possible नहीं है
Local processing की भी सीमा है। इसे छिपाना marketing fog है।
काम आपके device पर ही होता है। 5 MB का form और 400 MB का scanned document एक जैसे नहीं हैं। Browser memory, CPU, file complexity और library support सब फर्क डालते हैं।
PDF compress करना भी एक button जैसा दिखता है, पर अंदर कई फैसले होते हैं। Images downsample करनी हैं या नहीं। Unused objects हटाने हैं या नहीं। Streams फिर से लिखनी हैं या नहीं। Quality loss कितना ठीक है।
कुछ files अच्छी तरह छोटी हो जाती हैं। कुछ मुश्किल से बदलती हैं।
इसलिए अच्छा no-upload tool साफ़ कहता है कि वह क्या करता है और कहाँ रुकता है।
Privacy पर भी यही नियम लागू होता है। कोई tool WebAssembly इस्तेमाल करके भी file upload कर सकता है, अगर product ऐसा बनाया गया है। कोई tool खुद को browser-based कह सकता है और फिर भी आपकी उम्मीद से ज्यादा data बाहर भेज सकता है।
इसलिए शब्द नहीं, file path देखें।
अगर आप care करते हैं, DevTools खोलें। Network tab देखें। एक test PDF डालें। File चुनने के बाद कोई बड़ा outbound request बनता है या नहीं, यह देखें। Result document upload के बिना बनता है या नहीं, यह भी देखें।
Footer की मुलायम privacy line से यह test बेहतर है।
No-upload PDF tool को कैसे परखें
आपको browser engine audit करने की ज़रूरत नहीं है।
बस इतना देखिए:
-
File बाहर जा रही है या नहीं। No-upload flow में PDF खुद किसी document-processing endpoint पर नहीं जानी चाहिए।
-
Page load के बाद काम चलता है या नहीं। Local tool app code load होने के बाद भी काम कर सकता है। हर operation fresh server round trip माँगता है तो वजह होनी चाहिए।
-
Worker behavior दिखता है या नहीं। Progress indicator, cancel state और responsive UI यह संकेत दे सकते हैं कि heavy work main thread पर नहीं पड़ा है।
-
Limits साफ़ लिखी हैं या नहीं। अच्छा local tool file size और browser memory limits मानता है। धुंधले वादे feature नहीं होते।
-
काम के हिसाब से tool चुनें। Share करने से पहले file छोटी करनी है तो browser-first PDF compressor देखें। Sensitive file है तो final copy भेजने से पहले metadata cleanup भी ठीक रहता है।
PDFTasker की बनावट भी जानबूझकर boring है। Service browser-side processing, static pages और workers पर टिकी है। Default रास्ता server-side document queue नहीं है।
Fancy दिखने के लिए नहीं।
बस उस सवाल को कम करने के लिए: upload के बाद मेरी file कहाँ गई?
Boring architecture ही मुद्दा है।
अच्छा browser-based PDF tool नाटक नहीं करता।
आप file चुनते हैं। Browser उसे पढ़ता है। Worker heavy काम करता है। Local result बनता है। आप download करते हैं।
बस।
अगर file को device छोड़ने की ज़रूरत नहीं है, तो उसे छोड़ना नहीं चाहिए। अगर upload चाहिए, tool को साफ़ कहना चाहिए।
Compress, merge, split, sign, protect या metadata cleanup जैसे रोज़मर्रा PDF कामों में browser अब पहले से ज्यादा जिम्मेदारी ले सकता है।
उसी का इस्तेमाल करें। Trust surface छोटा रखें।
PDFTasker
Compress