Por qué las herramientas PDF online suben tus archivos a un servidor
2026-04-22 · 5 min read · onnova
Te llegó un contrato por correo. Hay que firmarlo y devolverlo. Entonces buscas una herramienta para firmar PDF online, arrastras el archivo al primer resultado y te quedas mirando el spinner.
Ahí empieza el problema. Ese archivo puede haber salido ya de tu laptop y viajado a un servidor que no conoces. De una empresa cuyo nombre probablemente olvidarás mañana. Todo eso para poner una firma, unir unas páginas o ponerle contraseña a un documento.
¿Por qué esto se volvió normal? Porque la industria lo volvió costumbre. Sube el archivo. Espera. Lee “lo borramos después de una hora”. Confía y sigue.
Pero no tendría por qué funcionar así. Los navegadores actuales pueden hacer bastante trabajo por su cuenta. Sin vueltas. Sin cuenta. Sin mandar primero tu documento a la infraestructura de otro.
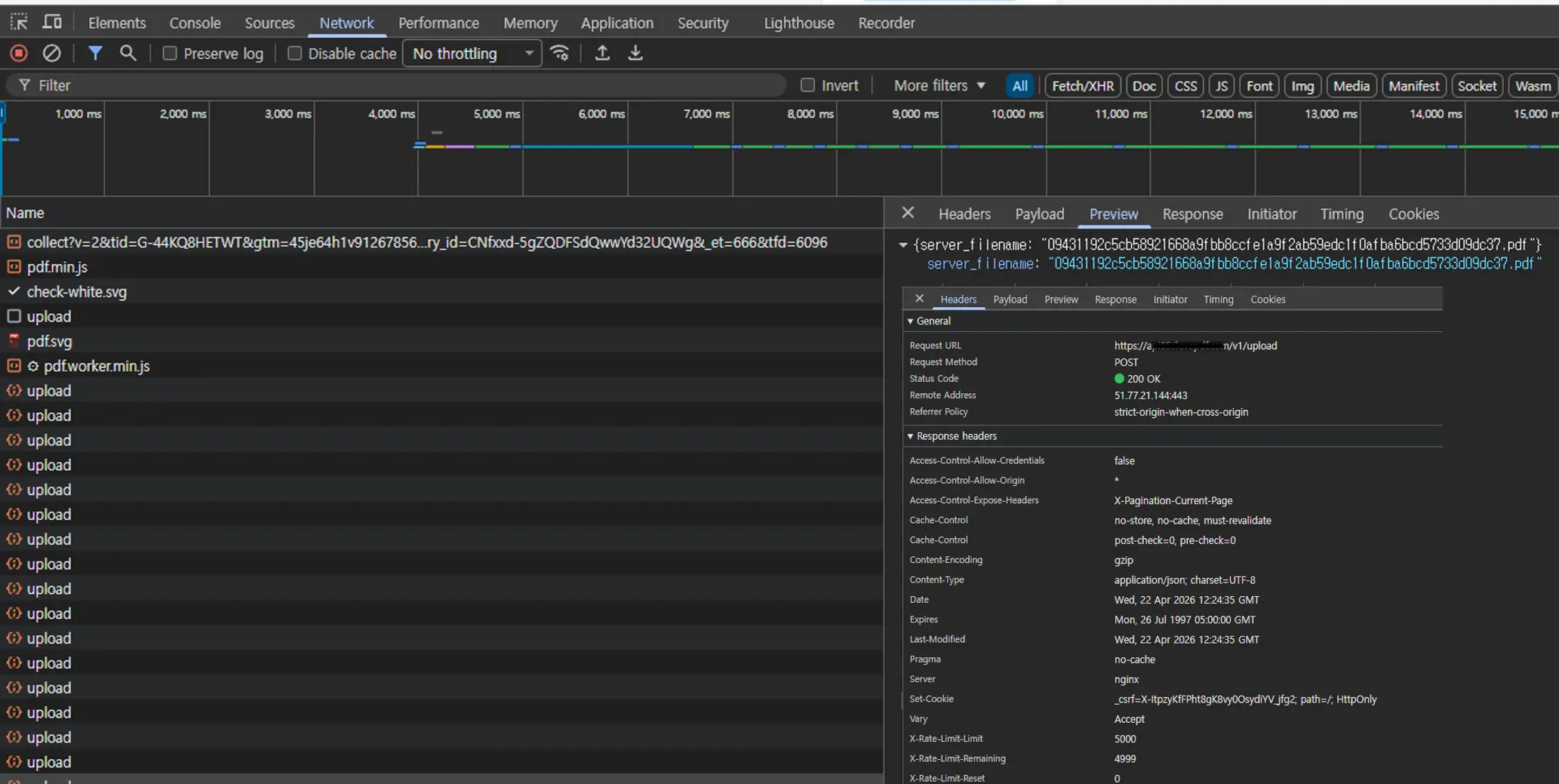
Qué pasa de verdad cuando sueltas un PDF en una web
Abre las herramientas de desarrollo del navegador y ve a la pestaña Network. Luego arrastra un PDF a una web de PDF online cualquiera. Muy seguido verás una petición POST que lleva el archivo como multipart/form-data a un endpoint de upload.
Eso significa que la web no solo te muestra una barra de progreso bonita. Está enviando tu documento fuera del navegador. El servidor recibe el archivo, lo guarda en algún lado, lo procesa y luego te devuelve otro archivo para descargar.
Desde ese momento, tu PDF original puede existir en más lugares de los que pensabas. Puede haber logs de la petición. Puede haber almacenamiento temporal. Puede haber backups. Puede haber carpetas de procesamiento. En ciertos setups también pueden intervenir otras capas operativas. No significa que haya una filtración. Significa que ya hay más sistemas metidos en el camino de tu documento.
Si es un archivo sin importancia, tal vez te da igual. Si es un contrato, una identificación, un archivo fiscal, un documento médico o un paquete de facturas, ya no da tan igual. ¿Por qué subir eso al servidor de otro?
“Borramos los archivos después de una hora” suena mejor de lo que vale
Esa frase aparece por todos lados. Suena tranquilizadora. Sigue siendo solo una promesa.
Tú no puedes verificar si el archivo realmente se borró. No ves su almacenamiento. No ves sus backups. No sabes si los logs siguen guardando el nombre del archivo, la hora, la IP u otros metadatos. Básicamente te piden confianza. En la empresa, en sus proveedores, en sus procesos y en su redacción.
Y la redacción importa. “Borramos después de una hora” casi siempre deja margen para excepciones: prevención de abuso, solicitudes legales, retención de backups, troubleshooting, logs operativos. A veces desaparece el archivo, pero no todo lo que quedó alrededor del archivo. Para documentos de bajo riesgo, mucha gente lo acepta. Para documentos sensibles, no alcanza.
La idea central es más simple: si el trabajo nunca necesitó un servidor, la promesa de privacidad no debería depender de que ese servidor se porte bien.

Tu navegador puede hacer este trabajo localmente
Esto ya no es ciencia ficción. El navegador puede ejecutar código serio. Existe WebAssembly. Existen librerías PDF en JavaScript. Existen workers para separar tareas pesadas de la interfaz. Muchas tareas PDF pueden resolverse ahí mismo: dividir, unir, poner marcas de agua, firmar, proteger y limpiar metadatos.
PDFTasker está planteado justo así. Su documentación técnica describe una app centrada en procesamiento dentro del navegador, entrega estática y manejo de archivos con workers, no en subir documentos a un app server para tareas rutinarias. En otras palabras: el trabajo ocurre en tu dispositivo.
Entonces, ¿por qué tantas herramientas siguen subiendo archivos? Porque el pipeline del lado del servidor le conviene al negocio. Facilita medir uso, poner límites, vender planes, empujar cuentas. Cómodo para la empresa. No necesariamente necesario para tu archivo.
Qué revisar antes de subir cualquier PDF
-
Abre primero la pestaña Network. Suelta el archivo y mira si aparece una petición POST grande.
-
Busca palabras como “retention”, “delete” o “logs” en la política de privacidad. Si el texto es vago, la responsabilidad también suele serlo.
-
Pregunta cuál es el modelo de negocio. Que algo sea gratis no lo vuelve malo. Pero gratis y sin explicación merece una pausa.
-
Para documentos sensibles, quédate en local. Puedes unir PDFs, firmar un PDF, protegerlo con contraseña o quitar metadatos sin subir el archivo primero.

PDFTasker
Firmar
Ese es el punto
Firmar un contrato no debería empezar con subirlo al servidor de otro. Así de simple.
Por eso PDFTasker toma el camino más directo. El archivo se queda en tu dispositivo. El navegador hace el trabajo. Tú terminas la tarea y sigues con tu día. Sin trucos. Sin rodeos. Y listo.