PDF en navegador sin servidor: qué cambia con WebAssembly
2026-04-27 · 6 min read · onnova
Abres una herramienta PDF. Arrastras un archivo. La barra de progreso se mueve.
Antes, la suposición era bastante simple: el archivo subía a un servidor, se procesaba allá y luego regresaba como descarga.
¿Por qué tendría que ser así por default?
Un PDF en navegador sin servidor es más viable desde que WebAssembly y Web Workers maduraron. El archivo puede quedarse en tu dispositivo mientras el navegador hace el trabajo localmente. Sin cola de servidor. Sin paso de upload escondido. Sin empezar confiando en una promesa de "lo borramos después".

El servidor fue el default porque el navegador antes era más chico
El modelo con servidor no apareció por tontería.
Un PDF no es solo una foto de páginas. Puede traer fuentes, imágenes, anotaciones, formularios, flujos comprimidos, metadatos, cifrado, árboles de páginas y varias rarezas históricas del formato. Leerlo y reescribirlo bien requiere código serio.
Los navegadores de antes no eran el mejor lugar para correr ese código. JavaScript era más lento. La memoria era más limitada. Un trabajo pesado podía congelar la página. Enviar una biblioteca grande de procesamiento de documentos a cada visitante tampoco era muy cómodo.
Así que la industria tomó el camino fácil.
Sube el archivo. Procésalo en el servidor. Devuelve el resultado.
Para el servicio, eso es cómodo. Para la persona con el archivo, no siempre. En cuanto el PDF sale de tu dispositivo, aparece una pregunta: ¿por dónde pasó después del upload?
Quizá el servicio sí lo borró rápido. Quizá registró metadatos. Quizá un worker temporal, un bucket de almacenamiento, un caché de CDN, un reporte de error o un backup alcanzó a ver más de lo que debería.
Quizá todo estuvo bien.
Aun así, la superficie de confianza creció.
WebAssembly hizo más realista el procesamiento local
WebAssembly no es magia de privacidad. Poner esa palabra en una página no vuelve privada a una herramienta.
WebAssembly permite correr código compilado dentro del navegador con un rendimiento cercano al nativo. Eso importa porque mucho tooling maduro para documentos no nació en JavaScript. Viene de C, C++, Rust y otros ecosistemas donde parsear archivos a bajo nivel es normal.
Con WebAssembly, más de ese trabajo puede correr dentro del navegador en vez de vivir detrás de un endpoint de upload.
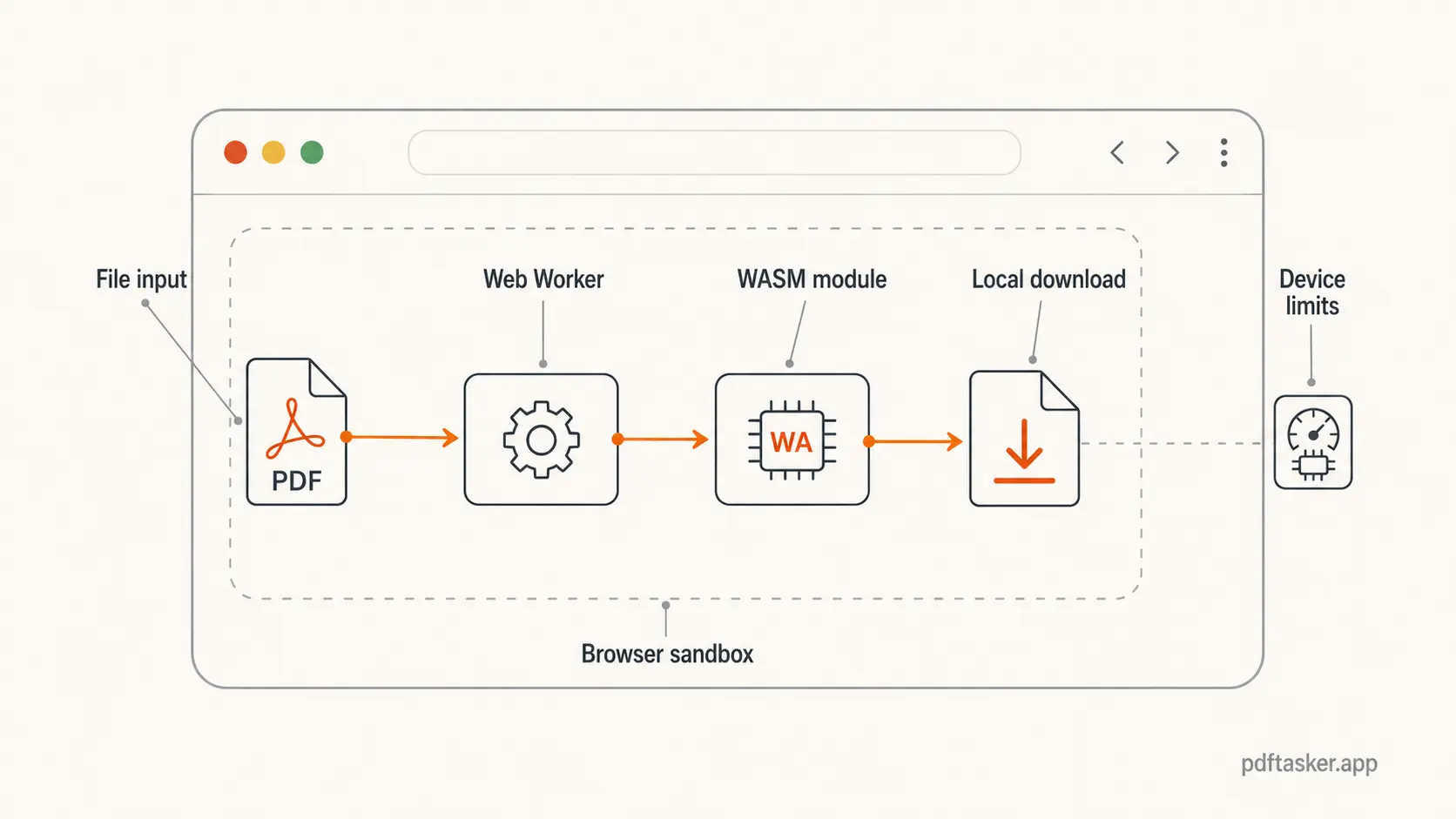
El navegador todavía tiene límites. El código corre dentro del sandbox del navegador. Puede leer el archivo que elegiste porque tú lo elegiste. No puede pasearse por tu disco sin más. El resultado puede generarse como un Blob y descargarse de vuelta.
Esa es la parte útil.
No tricks. El trabajo ocurre donde el archivo ya está.
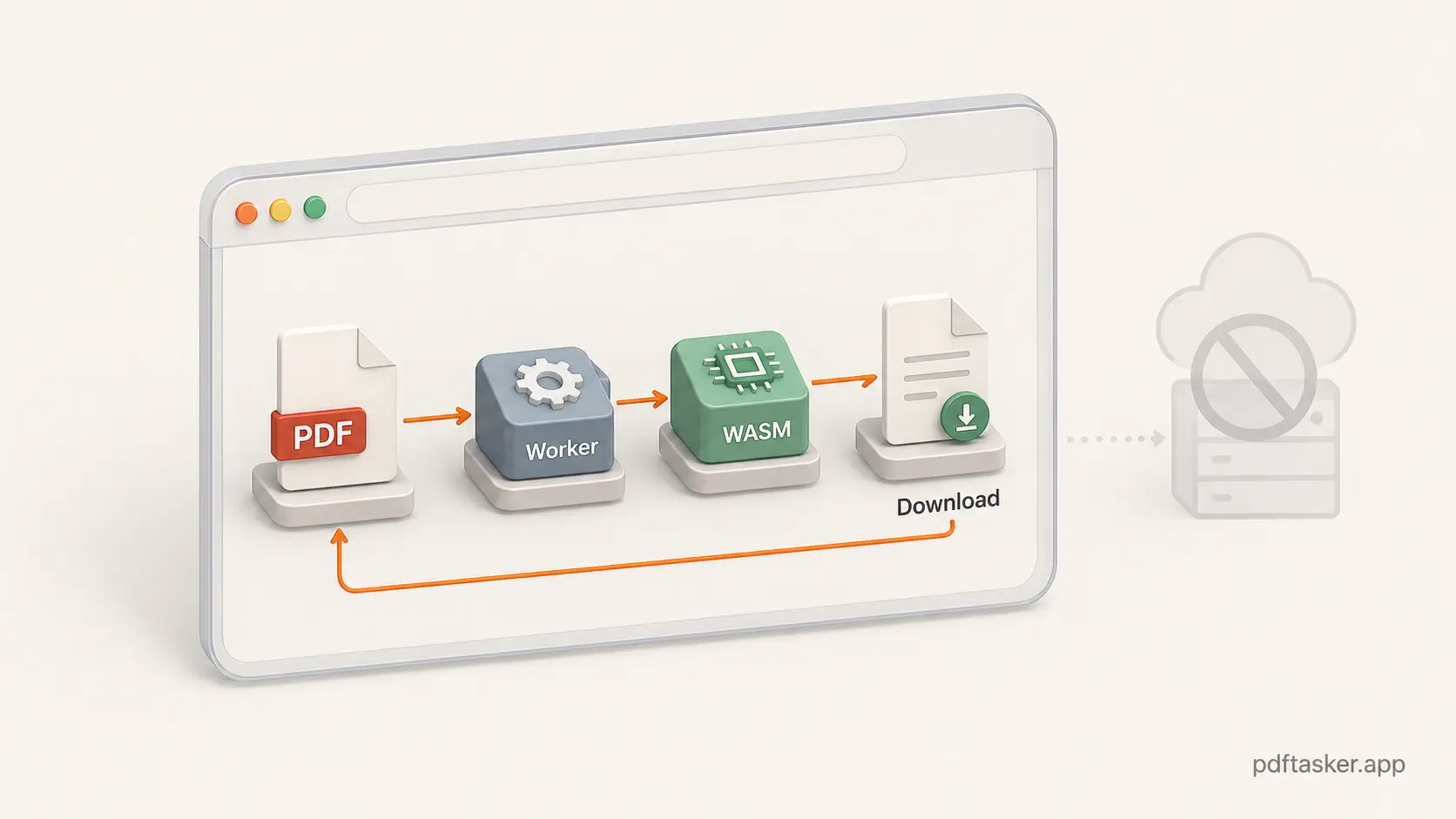
Los Web Workers completan la otra mitad. Si un trabajo pesado de PDF corre en el hilo principal de la interfaz, la página puede sentirse atorada. Un worker mueve ese trabajo a un lado para que la app siga mostrando progreso, errores y opciones de cancelación.
PDFTasker usa esa forma. La página estática carga. El trabajo de PDF pasa a workers del navegador y bibliotecas del lado del cliente. El resultado se crea localmente y se descarga.
Es una promesa más simple que "súbelo ahora y confía después".
Solo navegador no significa que todo sea posible
El procesamiento local también tiene límites. Fingir lo contrario ya es niebla de marketing.
Tu dispositivo sigue haciendo el trabajo. Un formulario de 5 MB y un documento escaneado de 400 MB no son la misma tarea. La memoria del navegador, el CPU, la complejidad del archivo y el soporte de las bibliotecas importan.
Comprimir un PDF tampoco es una sola acción. Puede implicar bajar resolución de imágenes, quitar objetos sin uso, reescribir flujos o decidir cuánta pérdida de calidad es aceptable. Algunos archivos bajan bastante. Otros casi no se mueven.
Por eso una buena herramienta no-upload debe decir qué hace y dónde están sus límites.
Lo mismo aplica a la privacidad. Una herramienta puede usar WebAssembly y aun así subir tu archivo si el producto fue construido así. Una herramienta puede decir "browser-based" y mandar más datos de los que esperabas.
Así que no juzgues por la palabra. Mira la ruta del archivo.
Si te importa, abre DevTools. Mira la pestaña Network. Usa un PDF de prueba. Revisa si aparece una solicitud grande hacia afuera después de elegir el archivo. Revisa también si el resultado aparece sin subir el documento.
Eso vale más que una frase suave de privacidad en el footer.
Cómo evaluar una herramienta PDF no-upload
No necesitas auditar un motor de navegador.
Con esto basta para una revisión práctica:
-
Mira si el archivo sale. Un flujo no-upload no debería enviar el PDF completo a un endpoint de procesamiento de documentos.
-
Revisa si la herramienta trabaja después de cargar la página. Una herramienta local puede seguir trabajando una vez que el código de la app ya cargó. Si cada operación necesita una vuelta nueva al servidor, conviene preguntar por qué.
-
Busca señales de workers. Indicadores de progreso, cancelación y una interfaz que sigue respondiendo durante trabajos pesados pueden señalar que no todo está en el hilo principal.
-
Lee los límites. Una buena herramienta local admite límites de tamaño de archivo y memoria del navegador. Las promesas vagas no son una función.
-
Usa la herramienta correcta para el trabajo correcto. Si necesitas reducir un archivo antes de compartirlo, prueba un compresor PDF centrado en el navegador. Si el archivo es sensible, también revisa la limpieza de metadatos antes de enviar la copia final.
Por eso PDFTasker mantiene una forma de producto bastante aburrida a propósito. El servicio está construido alrededor del procesamiento en el navegador, páginas estáticas y workers, no una cola de documentos en servidor.
No es para sonar sofisticado.
Es para reducir una pregunta completa: ¿qué pasó con mi archivo después del upload?
La arquitectura aburrida es el punto.
La mejor versión de una herramienta PDF en navegador no necesita teatro.
Eliges un archivo. El navegador lo lee. Un worker hace la parte pesada. Se crea un resultado local. Lo descargas.
Eso es todo.
Si el archivo no necesita salir de tu dispositivo, no debería salir. Si una herramienta necesita subirlo, debería decirlo claramente.
Para trabajos diarios como comprimir, unir, separar, firmar, proteger o limpiar metadatos, el navegador ya puede cargar más trabajo que antes.
Usa eso. Mantén pequeña la superficie de confianza.
PDFTasker
Comprimir