Por qué "se borra después de 1 hora" no es una promesa de privacidad
2026-04-23 · 6 min read · onnova
"El sitio dice que borra mi archivo después de una hora. ¿Con eso basta?"
La pregunta aparece cuando tienes que trabajar con una declaración de impuestos, un contrato, un documento escolar o un escaneo de identificación en una herramienta PDF gratis.
Respuesta corta: normalmente no.
El problema no es que el borrado con temporizador sea falso. Puede ser real. El problema es que responde una pregunta más pequeña que la que los usuarios creen que responde.
Responde sobre retención.
No responde sobre exposición.

La promesa empieza después de la parte riesgosa
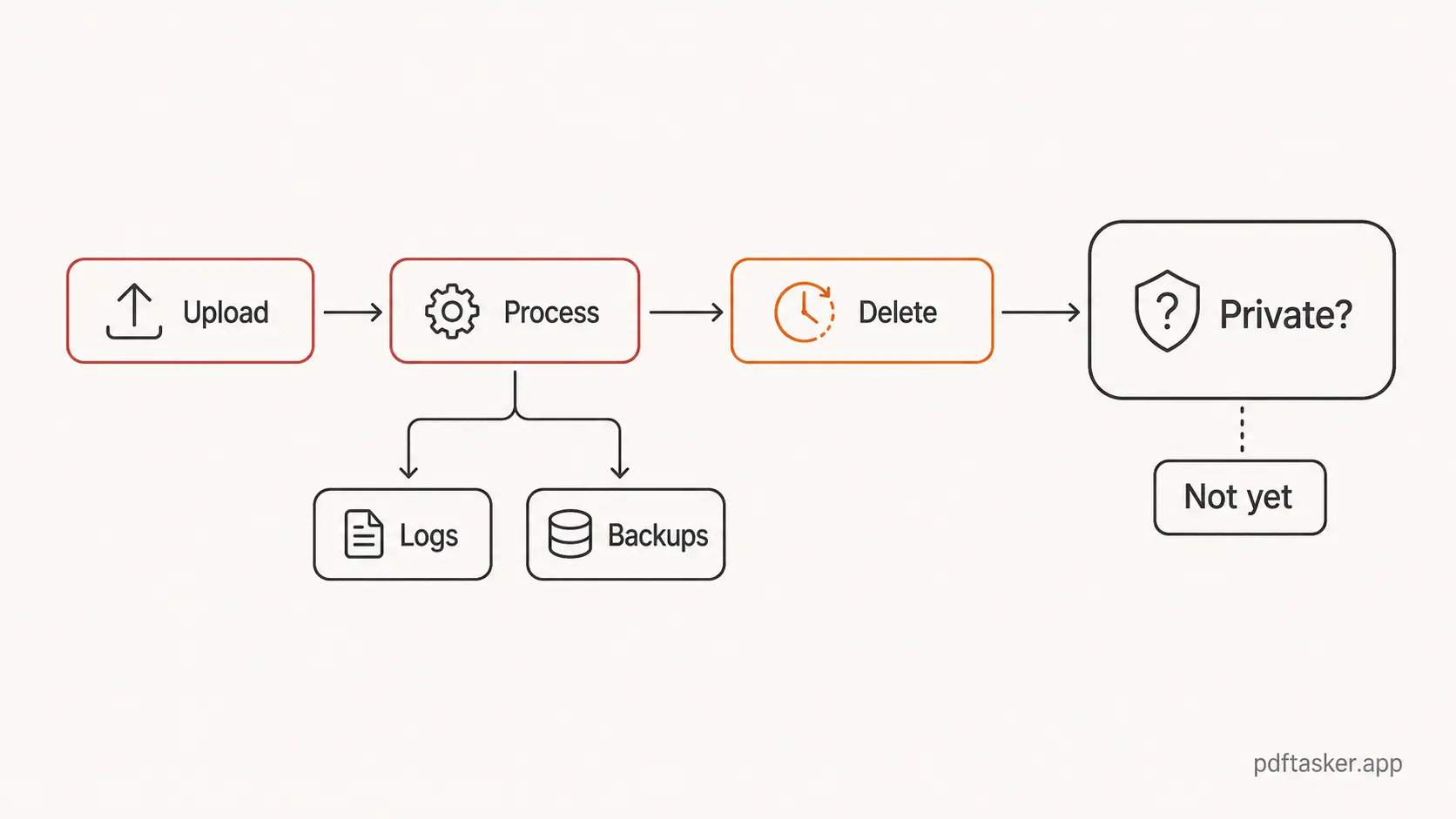
Las herramientas PDF que suben primero tienen una ruta sencilla. Eliges un archivo. El navegador lo manda a un servidor. El servidor hace el trabajo. Descargas el resultado. Después, el servicio puede borrar el archivo tras una ventana fija.
Ese último paso puede ser útil. Una ventana de retención corta es mejor que conservar archivos para siempre. No hay discusión ahí.
Pero no es lo mismo que privacidad.
Cuando un archivo llega a un servidor, la superficie de confianza se agranda. El texto principal puede decir que el archivo se borra después de una hora, pero el archivo quizá ya pasó por manejo de solicitudes, almacenamiento temporal, colas de procesamiento, logs, backups, monitoreo, reportes de error o infraestructura que nunca ves. Un buen servicio puede reducir esas rutas. Una promesa vaga no demuestra que lo hizo.
"Borrado después" no es la misma afirmación que "nunca subido."
Esa diferencia importa porque la mayoría de los usuarios lee la línea de forma emocional. Ven "1 hora" y escuchan "privado." El sistema escucha algo más limitado: "no pretendemos retener el archivo de trabajo después de este periodo."
No son la misma oración.
Tres patrones se esconden dentro de una línea de borrado en una hora
La confusión de privacidad alrededor de herramientas PDF online suele seguir el mismo patrón. El marketing habla del final de la vida del archivo. La preocupación real del usuario está al principio.
Patrón 1. La retención se confunde con privacidad
La retención trata sobre cuánto tiempo un servicio conserva algo.
La privacidad trata sobre quién obtiene acceso desde el inicio.
Se cruzan, pero no son intercambiables. Un archivo puede borrarse rápido y aun así haber sido manejado por un sistema remoto. Un archivo puede procesarse brevemente y aun así exponer nombres personales, números de factura, firmas, metadatos o estructura del documento a infraestructura fuera de tu dispositivo.
Por eso la frase "se borra después de 1 hora" puede sentirse más tranquilizadora de lo que debería. Comprime la parte difícil en un temporizador. El temporizador no es la parte difícil.
La parte difícil es si la subida era necesaria.
Patrón 2. La "transferencia segura" se vuelve toda la historia
Otra línea común es el cifrado en tránsito. También es algo bueno. Y también es plomería básica.
HTTPS protege un archivo mientras se mueve entre tu navegador y un servidor. No significa que el servidor nunca reciba el archivo. No explica qué pasa durante el procesamiento. No te dice si una copia entra a una cola, un cache, una ruta de debug o un flujo de soporte.
Así que la pregunta útil no es "¿la tubería estaba cifrada?"
Debería estarlo.
La mejor pregunta es: ¿por qué el archivo tenía que entrar a esa tubería?
Patrón 3. El "borrado automático" tapa la arquitectura
El borrado automático suena limpio desde la operación. En muchos sistemas, probablemente lo es. Corre un job. Desaparecen los archivos temporales. El equipo de producto puede señalar una política y un temporizador.
Pero la arquitectura todavía importa.
Si el trabajo requiere un servidor, el usuario tiene que confiar en ese proceso del lado del servidor. Si el trabajo puede ocurrir dentro del navegador, el usuario evita ese paso extra de confianza. Esa es la diferencia.
Un modelo dice: "Confía en que quitaremos el archivo después."
El otro dice: "No necesitamos el archivo en nuestro servidor para esta tarea."
Son modelos operativos distintos, no solo líneas de copy distintas.

Cómo se ve una superficie de confianza más pequeña
El mejor modelo de privacidad es más pequeño, no más ruidoso.
Para trabajo PDF cotidiano, un producto browser-first puede cargar la app, dejar que elijas un archivo, pasar los bytes a un Web Worker, ejecutar la operación localmente y devolver el resultado como descarga. El servidor puede alojar el sitio sin convertirse en el lugar donde se procesa tu documento.
PDFTasker está diseñado alrededor de eso: páginas estáticas, procesamiento en el navegador, Web Workers y descargas locales. El contexto más amplio está en la página About, pero lo importante es simple. El trabajo con documentos está pensado para ocurrir en tu dispositivo, no en una cola de documentos que operamos nosotros.
Eso no vuelve mágicamente libre de riesgo a cada archivo. Tu navegador sigue importando. Tu dispositivo también. El documento que compartes después de descargarlo también. Si un PDF contiene nombres de autor, historial de revisión, metadatos incrustados u otros rastros, conviene limpiarlo antes de enviarlo.
Ahí ayuda un paso local de limpieza de metadatos PDF. Reduce lo que el documento saliente dice sobre ti antes de que alguien más lo reciba.
Si el documento es lo bastante sensible como para controlar el acceso, también puedes proteger el PDF con contraseña antes de compartirlo. La protección con contraseña tampoco es una historia de privacidad por sí sola. Solo es otra capa práctica.
El patrón es el mismo: afirmaciones más pequeñas, superficie de confianza más pequeña, menos palabras mágicas.
Cómo leer copy de privacidad sin volverte abogado
No necesitas una auditoría de seguridad para cada tarea PDF pequeña. Solo necesitas unas preguntas más precisas.
- ¿La herramienta empieza subiendo el archivo antes de mostrar trabajo real?
- ¿El texto de privacidad explica dónde ocurre el procesamiento, o solo cuándo ocurre el borrado?
- ¿El producto habla de trabajo en el navegador, procesamiento local o Web Workers de manera concreta?
- ¿Hace afirmaciones estrechas, o agita palabras amplias como "seguro" esperando que dejes de leer?
El último punto suele delatarlo.
El buen copy de privacidad normalmente es aburrido. Dice qué pasa y qué no. No te pide inferir la arquitectura desde un temporizador de borrado.
PDFTasker
Borrar metadatos
Si estás limpiando un PDF antes de enviarlo, empieza con la parte que controlas. Quita los metadatos localmente. Comparte menos. Confía en menos infraestructura. No suena dramático.
Es solo la parte que sí ayuda.