"1시간 후 삭제"는 프라이버시 약속이 아닙니다
2026-04-24 · 13 min read · onnova
"사이트가 내 파일을 1시간 뒤 삭제한다고 합니다. 그럼 충분한가요?"
무료 PDF 도구로 세금 서류, 계약서, 학교 문서, 신분증 스캔본을 다룰 때 자주 나오는 질문입니다.
짧게 말하면, 보통은 아닙니다.
예약 삭제가 거짓이라는 뜻은 아닙니다. 실제로 삭제할 수 있습니다. 문제는 그 약속이 사용자가 기대하는 질문보다 훨씬 작은 질문에 답한다는 점입니다.
그 문구는 보관 기간에 답합니다.
노출 범위에는 답하지 않습니다.

약속은 위험한 구간 뒤에서 시작됩니다
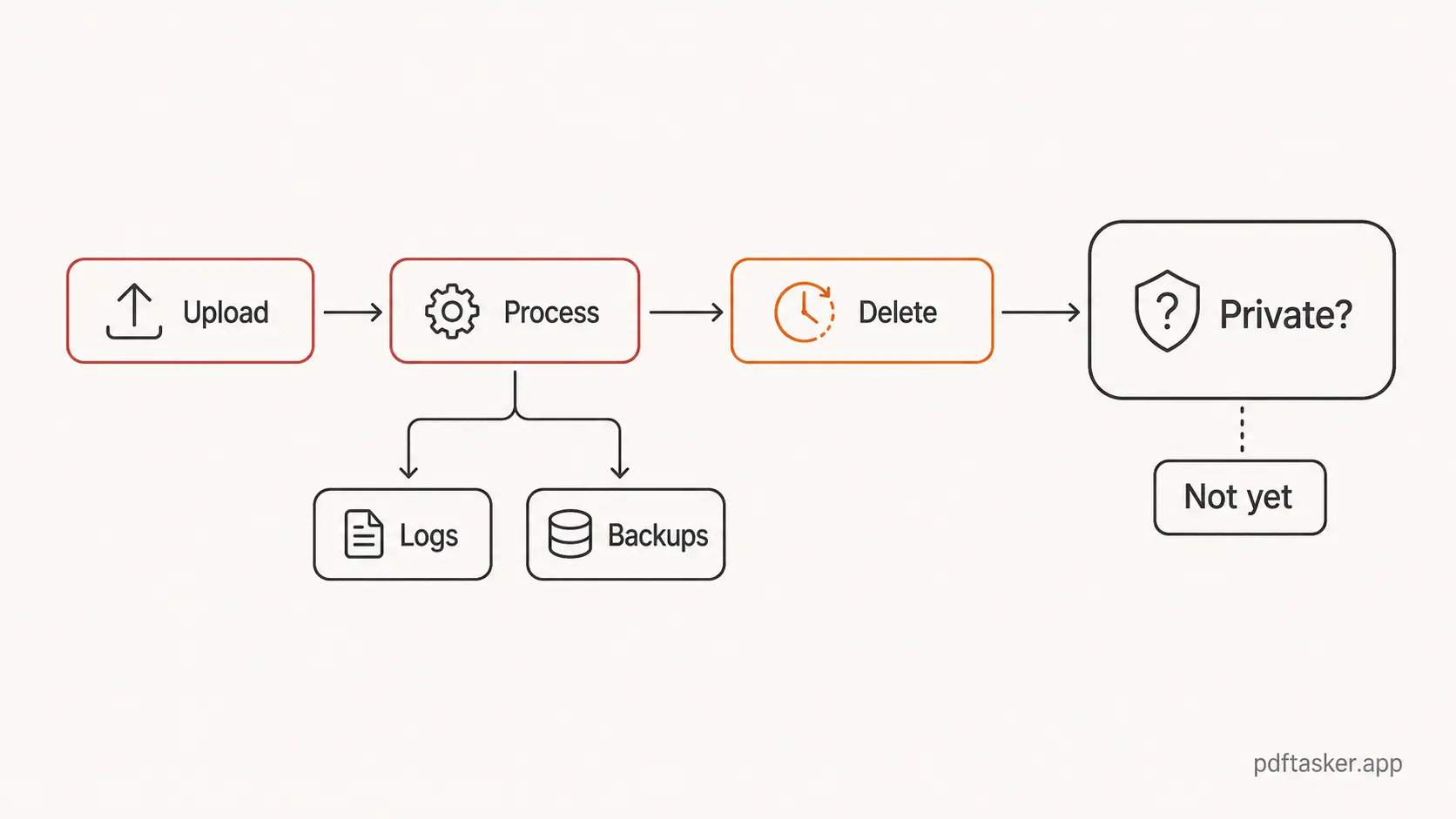
업로드 우선 PDF 도구의 흐름은 단순합니다. 파일을 고릅니다. 브라우저가 서버로 보냅니다. 서버가 작업합니다. 결과를 내려받습니다. 그다음 서비스가 정해진 시간 뒤 파일을 삭제할 수 있습니다.
마지막 단계가 쓸모없다는 뜻은 아닙니다. 짧은 보관 기간은 파일을 계속 쌓아두는 것보다 낫습니다. 그 부분은 맞습니다.
하지만 그것은 프라이버시와 같지 않습니다.
파일이 서버에 도착하는 순간 신뢰해야 할 범위가 넓어집니다. 화면의 문구는 "1시간 후 삭제"라고 말할 수 있지만, 그 파일은 이미 요청 처리, 임시 저장소, 처리 큐, 로그, 백업, 모니터링, 오류 리포트, 사용자가 볼 수 없는 인프라를 지나갔을 수 있습니다. 좋은 서비스는 이런 경로를 줄입니다. 막연한 문구만으로는 실제로 줄였는지 알 수 없습니다.
"나중에 삭제합니다"는 "처음부터 업로드하지 않습니다"와 같은 말이 아닙니다.
이 차이가 중요합니다. 대부분의 사용자는 "1시간"이라는 문구를 감정적으로 읽습니다. 눈에는 "1시간"이 보이고, 귀에는 "안전하다"처럼 들립니다. 시스템이 실제로 말하는 것은 더 좁습니다. "작업 파일을 이 기간 뒤 보관하지 않으려 합니다"에 가깝습니다.
두 문장은 같지 않습니다.
1시간 삭제 문구 안에 숨어 있는 세 가지 패턴
온라인 PDF 도구의 프라이버시 혼란은 대체로 같은 패턴을 따릅니다. 마케팅 문구는 파일 생애의 끝을 말합니다. 사용자가 진짜 궁금해하는 것은 시작 부분입니다.
패턴 1. 보관 기간을 프라이버시로 착각합니다
보관 기간은 서비스가 어떤 것을 얼마나 오래 갖고 있는지에 관한 이야기입니다.
프라이버시는 처음부터 누가 접근할 수 있는지에 관한 이야기입니다.
둘은 겹치지만 서로 바꿔 쓸 수 없습니다. 파일은 빨리 삭제될 수 있지만, 그 전에 원격 시스템을 거쳤을 수 있습니다. 짧게 처리됐더라도 개인 이름, 송장 번호, 서명, 메타데이터, 문서 구조가 내 기기 밖의 인프라에 노출될 수 있습니다.
그래서 "1시간 후 삭제"는 실제보다 더 안심되는 문장처럼 느껴집니다. 어려운 문제를 타이머 하나로 압축하기 때문입니다. 타이머가 어려운 부분은 아닙니다.
어려운 부분은 업로드가 필요했는지입니다.
패턴 2. 보안 전송이 이야기 전체가 됩니다
또 자주 보이는 문구가 전송 중 암호화입니다. 이것도 좋은 일입니다. 동시에 기본 배관에 가깝습니다.
HTTPS는 파일이 브라우저와 서버 사이를 이동하는 동안 보호합니다. 서버가 파일을 받지 않는다는 뜻은 아닙니다. 처리 중 어떤 일이 일어나는지도 설명하지 않습니다. 파일 사본이 큐, 캐시, 디버그 경로, 지원 워크플로우에 들어가는지 알려주지도 않습니다.
그래서 유용한 질문은 "파이프가 암호화됐나요?"가 아닙니다.
그건 당연히 그래야 합니다.
더 나은 질문은 이것입니다. 왜 파일이 그 파이프 안으로 들어가야 했나요?
패턴 3. 자동 삭제가 구조를 가립니다
자동 삭제는 운영상 깔끔하게 들립니다. 많은 시스템에서는 실제로 그럴 수 있습니다. 작업이 실행되고, 임시 파일이 사라지고, 제품팀은 정책과 타이머를 보여줄 수 있습니다.
하지만 구조는 여전히 중요합니다.
작업에 서버가 필요하다면 사용자는 그 서버 쪽 처리를 신뢰해야 합니다. 작업이 브라우저 안에서 가능하다면 그 추가 신뢰 단계를 피할 수 있습니다. 차이는 여기에 있습니다.
한 모델은 이렇게 말합니다. "나중에 파일을 지우는 우리를 믿어주세요."
다른 모델은 이렇게 말합니다. "이 작업에는 우리 서버에 파일이 필요하지 않습니다."
이 둘은 문구 차이가 아니라 운영 모델의 차이입니다.

더 작은 신뢰 범위는 어떤 모습인가요
더 나은 프라이버시 모델은 더 크게 말하는 모델이 아니라 더 작게 믿어도 되는 모델입니다.
일상적인 PDF 작업에서는 브라우저 우선 제품이 앱을 로드하고, 사용자가 파일을 선택하고, 바이트를 Web Worker에 넘기고, 작업을 로컬에서 실행한 뒤 결과를 다운로드로 돌려줄 수 있습니다. 서버는 웹사이트를 호스팅할 수 있지만, 사용자의 문서를 처리하는 장소가 될 필요는 없습니다.
PDFTasker는 이 방향으로 설계되어 있습니다. 정적 페이지, 브라우저 측 처리, Web Worker, 로컬 다운로드가 중심입니다. 더 넓은 제품 설명은 About 페이지에 있지만, 중요한 부분은 단순합니다. 문서 작업은 우리가 운영하는 문서 큐가 아니라 사용자의 기기에서 일어나도록 설계되어 있습니다.
그렇다고 모든 파일이 자동으로 위험이 없어지는 것은 아닙니다. 브라우저도 중요합니다. 기기도 중요합니다. 다운로드한 뒤 공유하는 문서도 중요합니다. PDF에 작성자 이름, 수정 이력, 내장 메타데이터, 그 밖의 흔적이 남아 있다면 보내기 전에 정리해야 합니다.
이럴 때 로컬 PDF 메타데이터 정리 단계가 도움이 됩니다. 다른 사람이 파일을 받기 전에, 나가는 문서가 나에 대해 말하는 내용을 줄입니다.
민감한 문서라면 공유 전에 PDF에 비밀번호를 설정하는 것도 고려할 수 있습니다. 비밀번호 보호도 그 자체로 프라이버시 이야기는 아닙니다. 실용적인 한 겹일 뿐입니다.
패턴은 같습니다. 더 작은 주장, 더 작은 신뢰 범위, 덜 마법 같은 단어입니다.
변호사가 되지 않고 프라이버시 문구 읽기
작은 PDF 작업마다 보안 감사를 할 필요는 없습니다. 대신 몇 가지 질문을 더 날카롭게 던지면 됩니다.
- 이 도구는 실제 작업을 보여주기 전에 먼저 파일을 업로드하나요?
- 프라이버시 문구가 처리 위치를 설명하나요, 아니면 삭제 시점만 설명하나요?
- 제품이 브라우저 측 작업, 로컬 처리, Web Worker를 구체적으로 말하나요?
- 좁고 확인 가능한 주장을 하나요, 아니면 "secure" 같은 넓은 단어를 던지고 읽기를 멈추길 바라나요?
마지막 질문이 단서입니다.
좋은 프라이버시 문구는 대체로 심심합니다. 무엇이 일어나고 무엇이 일어나지 않는지 말합니다. 삭제 타이머에서 구조를 추론하라고 요구하지 않습니다.
PDFTasker
메타 지우기
PDF를 보내기 전에 정리하려면, 먼저 내가 통제할 수 있는 부분부터 시작하세요. 메타데이터를 로컬에서 지우세요. 덜 공유하세요. 덜 많은 인프라를 믿으세요. 극적인 이야기는 아닙니다.
그냥 실제로 도움이 되는 부분입니다.