스캔한 PDF에서 텍스트를 무료로 추출하는 방법 (로컬 OCR)
2026-06-26 · 10 min read · onnova
중요한 업무 계약서, 스캔된 영수증 묶음, 혹은 제본된 학습 자료 PDF를 열었는데 마우스 드래그도, 글자 선택도, 복사도 되지 않아 답답했던 적이 있으신가요?
텍스트 데이터가 들어있는 것이 아니라, 글자가 찍힌 사진 이미지가 문서 프레임 안에 껍데기처럼 들어가 있는 경우입니다. 이른바 이미지 기반 스캔본 PDF입니다.
여기에 적힌 글자를 타이핑하기 위해 내용을 직접 받아적거나, 무료 온라인 PDF OCR 사이트를 검색해 문서 전체를 업로드하곤 합니다.
하지만 금융 명세서나 기밀 계약서 같은 민감한 파일을 외부 서버로 보내기 전에, 그 문서들이 실제로 안전한지, 그리고 브라우저 내 로컬 환경에서 안전하게 글자를 긁어오는 대안은 없는지 살펴볼 필요가 있습니다.
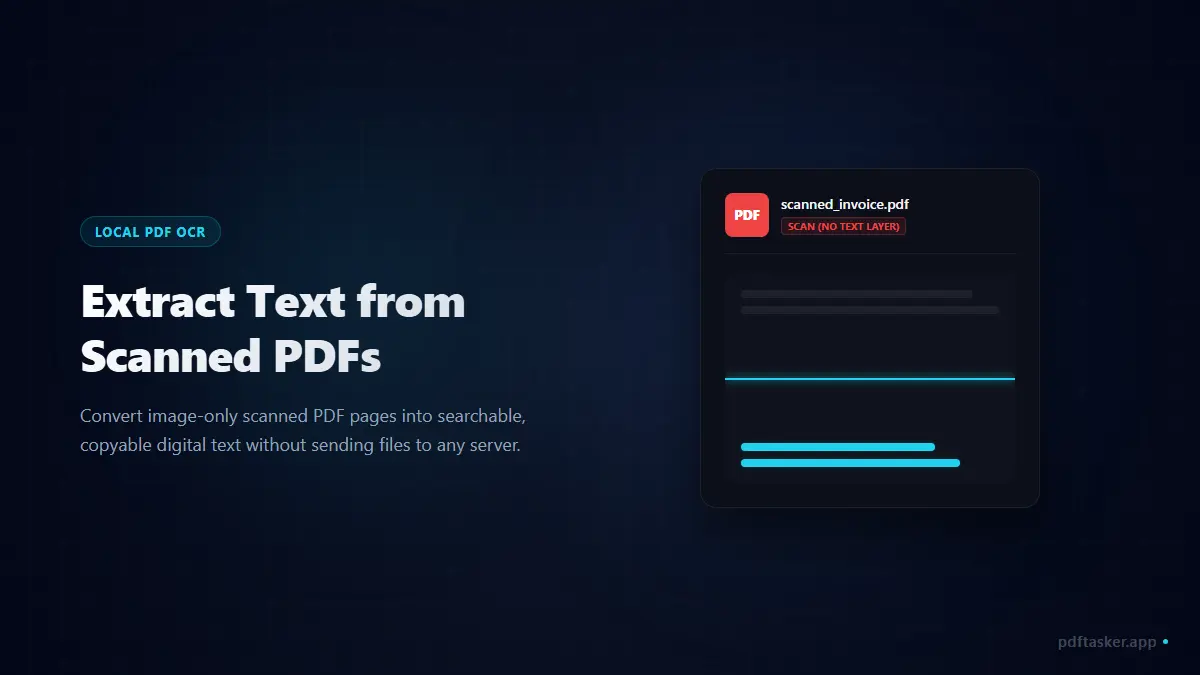
스캔한 PDF와 일반 PDF의 구조적 차이
일부 PDF 파일에서 일반적인 복사-붙여넣기가 작동하지 않는 이유는 파일 내부 구조가 근본적으로 다르기 때문입니다.
- 디지털 생성 PDF (텍스트 내장형): MS Word, 한글, Google 문서 등에서 'PDF로 저장'하여 내보낸 파일입니다. 글자의 좌표 정보, 폰트 규격, 텍스트 데이터 레이어가 파일 안에 살아 있어 마우스 드래그와 복사가 즉시 작동합니다.
- 스캔본 PDF (이미지 단독형): 종이 문서를 스캔했거나, 스마트폰 카메라로 촬영한 이미지들을 PDF로 결합하여 내보낸 파일입니다. 텍스트 레이어가 없고 오직 페이지 크기의 고정 이미지 파일들로만 채워져 있어 컴퓨터는 이를 글자가 아닌 하나의 거대한 그림으로 인식합니다.
일반적인 텍스트 추출 도구에 스캔본 PDF를 넣으면 아무런 글자도 나오지 않는 빈 파일이 반환됩니다. 컴퓨터가 읽을 글자가 없기 때문이죠. 이 경우 이미지를 판독해 글자를 해독해내는 광학 문자 인식(OCR) 기능이 반드시 동반되어야 합니다.
온라인 클라우드 OCR 사이트가 지닌 보안 취약점
인터넷상의 수많은 무료 OCR 도구들은 사용자가 올린 PDF 파일을 자신들의 원격 웹 서버로 가져가 처리합니다. 서버에 파일을 임시 저장하고, 각 페이지를 이미지로 변환한 뒤, 서버 성능을 활용해 문자를 추출하고 결과물을 되돌려줍니다.
이 클라우드 방식은 편리해 보이지만 중요한 정보 보안 리스크를 안겨줍니다.
- 통제권 상실: 원본 파일이 네트워크를 타고 외부 서버에 전달되는 순간, 해당 사이트의 캐시 서버나 임시 파일 경로에 문서가 어떻게 백업되고 보관되는지 통제할 수 없습니다.
- 컴플라이언스 위반: 회계 자료, 진료 기록, 개인 식별 정보가 가득한 업무 서식을 사설 클라우드 서버에 올리는 것은 기업의 내부 정보 보호 지침 및 규제에 저촉됩니다.
- 대역폭 낭비 및 대기 시간: 고용량 스캔 PDF를 업로드하고 변환 작업이 끝날 때까지 서버 대기 큐에서 마냥 기다려야 하므로 작업 흐름이 끊깁니다.
민감한 문서일수록, 글자 몇 줄을 추출하기 위해 파일 전체를 외부 서버로 업로드하는 행위는 지양해야 합니다.
브라우저 내부에서 작동하는 PDF OCR 폴백 원리
최신 웹 기술을 사용하면 외부 서버로 파일을 단 1바이트도 보내지 않고 브라우저 내부에서 직접 스캔 PDF를 래스터화하여 텍스트를 추출해낼 수 있습니다.
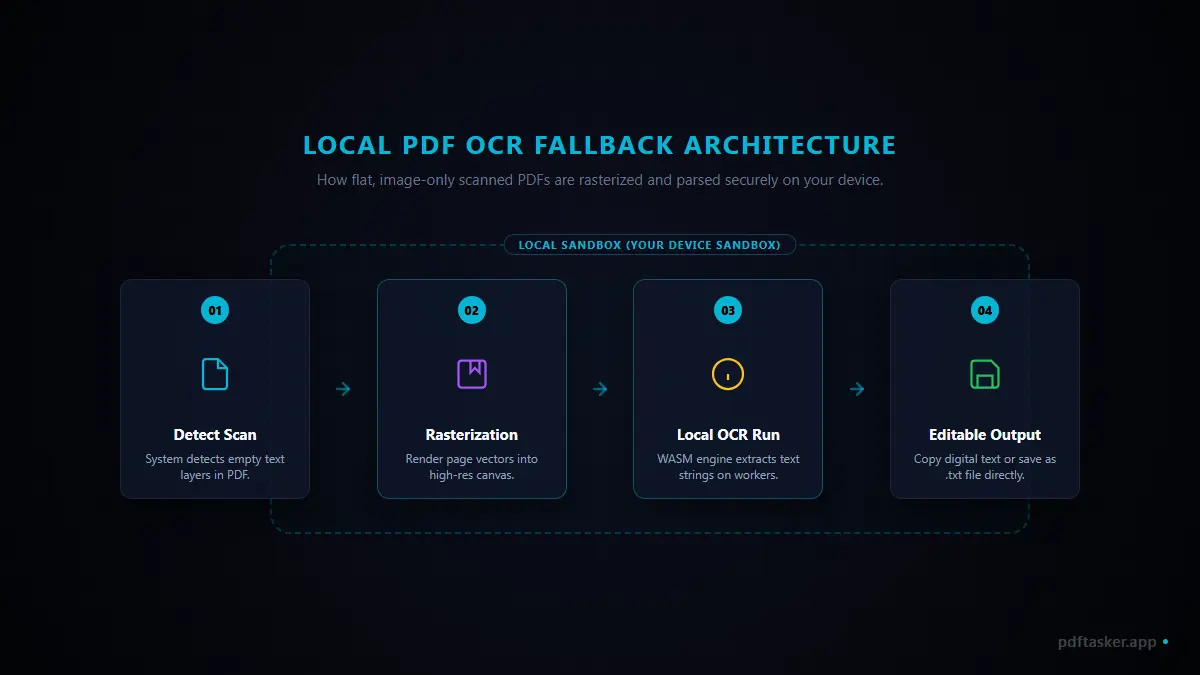
스캔 PDF가 추가되면 다음과 같은 단계로 처리됩니다.
- 텍스트 레이어 검사: 도구가 문서를 읽어내며 텍스트 레이어가 존재하는지 1차 확인합니다.
- 스캔본 자동 감지: 글자 데이터가 존재하지 않는 스캔본임이 확인되면 사용자에게 OCR 기능을 안내합니다.
- 로컬 래스터화: 브라우저 렌더러가 PDF의 이미지 스트림을 분석하여 브라우저 내 보이지 않는 영역에 페이지 레이아웃을 이미지로 가상 렌더링합니다.
- 기기 내 OCR 구동: 사용자 브라우저에 컴파일된 tesseract.js 엔진과 한국어·영어 언어 모델을 올려 컴퓨터 프로세서가 직접 글자를 인식합니다.
- 텍스트 반환: 판독 완료된 텍스트 데이터만 화면에 안전하게 뿌려줍니다.
원본 문서가 외부 서버로 절대 유출되지 않으므로 사내 보안망 안에서도 편안하게 업무 기밀 문서를 해독할 수 있습니다.
스캔 PDF에서 로컬로 글자를 추출하는 순서
기기 내부에서 문서를 안전하게 긁어오는 구체적인 사용법은 다음과 같습니다.
- 도구 페이지 열기: 브라우저에서 Extract Text 도구로 이동합니다.
- PDF 문서 로드: 텍스트를 추출하고 싶은 스캔본 PDF 파일을 선택합니다.
- OCR 실행 클릭: 글자 레이어가 없는 스캔본임이 감지되면 화면에 나타나는 OCR로 텍스트 추출 버튼을 클릭합니다.
- 진행 상태 모니터링: 백그라운드 웹 워커가 로컬에서 언어 모델을 활성화하고 페이지를 해독하는 과정을 편안하게 확인합니다.
- 텍스트 저장: 해독이 끝나면 결과 상자의 글자들을 복사하거나 깔끔한
.txt파일로 다운로드합니다.
글자가 깨져 있거나 스캔 해상도가 낮으면 간혹 오타가 섞일 수 있으므로 수식이나 숫자, 서명 근처의 텍스트는 최종 제출 전에 가볍게 눈으로 검토하는 습관이 좋습니다.
브라우저 기반의 로컬 개인정보 보호 모델이 왜 기존 클라우드 방식보다 안전한지에 대한 자세한 설명은 비교 페이지에서 확인 가능하며, 단일 사진 파일에서 글자를 추출하는 방법은 이미지 텍스트 추출 가이드를 참고해 보세요.
PDFTasker
텍스트 추출