로그인 없이, 사진 속 글자를 텍스트로 무료 추출하는 방법
2026-06-25 · 10 min read · onnova
에러 메시지가 뜬 화면을 캡처한 스크린샷, 영수증 사진, 또는 프레젠테이션 슬라이드의 일부에서 본문 텍스트만 긁어 복사하고 싶었던 적이 얼마나 많으신가요?
이것은 현대 업무 환경에서 가장 흔히 일어나는 단순 반복 작업 중 하나입니다. 하지만 대개의 해결책은 이미지를 검색 엔진의 텍스트 인식기에 끌어다 놓거나, 웹상의 무료 온라인 이미지-텍스트 변환 사이트에 업로드하는 것입니다.
고객 정보가 포함된 문서, 계정 자격증명 스크린샷, 또는 기밀 업무 영수증을 외부 브라우저 창으로 드래그하기 전에, 그 이미지 파일이 실제로 어디로 전송되는지, 그리고 서버 전송 없이 완전히 기기 내부에서 처리할 수 있는 방법은 없는지 짚고 넘어갈 필요가 있습니다.

온라인 이미지 변환 사이트가 품고 있는 잠재적 리스크
이미지 파일 내의 글자 레이어를 해독해 편집 가능한 텍스트로 바꾸는 기술을 광학 문자 인식(OCR, Optical Character Recognition)이라고 합니다. 전통적으로 이 작업을 수행하려면 무거운 전문 소프트웨어를 설치하거나 상당한 서버 연산 자원을 소모해야 했습니다.
기존의 무료 웹 변환기들은 이 OCR 엔진을 서버측에 올려두는 방식을 선택했습니다. 사용자가 JPG나 PNG 이미지를 올리면 서버가 이미지를 파싱해 텍스트를 해독한 뒤 웹 화면에 뿌려주는 것이죠.
하지만 이 단순한 방식 뒤에는 몇 가지 보안상 아쉬운 점이 따릅니다.
- 민감 자산의 외부 전송: 데이터베이스 오류 화면이나 회사 경비 영수증 사진 등에는 외부 서버 임시 디렉토리에 그냥 남겨두기 꺼려지는 민감한 식별 정보가 가득합니다.
- 불투명한 삭제 정책: 사이트가 '1시간 후 자동 삭제'를 약속하더라도, 그 과정에서 남는 데이터베이스 로그, CDN 캐시, 임시 파일 백업 등은 사용자가 직접 확인할 수 없는 영역에 저장됩니다.
- 사내 데이터 보안 규정 위반: 업무용 중요 자산을 신뢰성이 검증되지 않은 외부 클라우드 처리 서버로 드래그하는 행위는 기본적인 사내 보안 지침이나 개인정보보호법에 어긋날 수 있습니다.
단순히 텍스트 몇 줄을 긁어내기 위해 소중한 문서를 외부 서버로 내보내는 것은 불필요한 위험 부담입니다.
내 기기 안에서 직접 구동하는 OCR 엔진
사진에서 글자를 읽어내기 위해 굳이 원격 서버의 도움을 받을 필요는 없습니다. 최신 웹 브라우저는 텍스트 인식 엔진을 기기 로컬 메모리에 직접 로드하여 처리할 수 있을 만큼 강력해졌기 때문입니다.
브라우저 내 클라이언트 사이드 웹 워커(Web Worker) 기술을 이용하면, 페이지가 처음 로드될 때 OCR 엔진을 로컬 브라우저에 안전하게 내려받아 구동합니다.
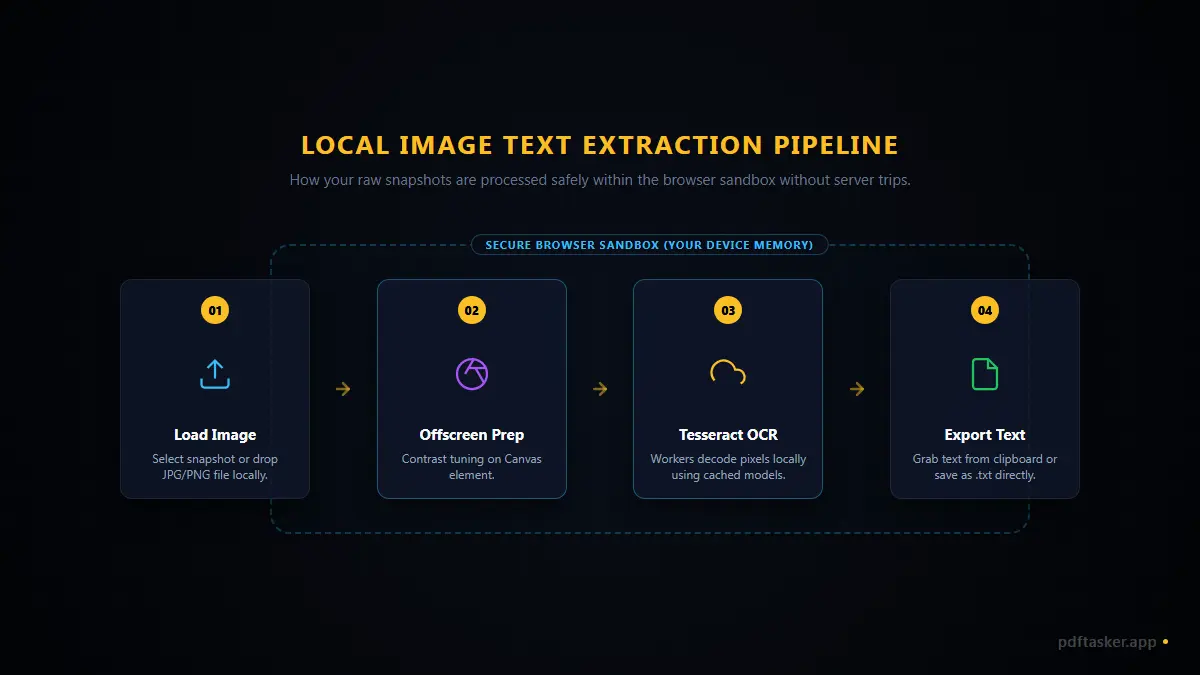
사용자가 사진을 추가하면 다음과 같이 처리됩니다.
- 기기 내 로드: 이미지 파일이 웹 서버가 아닌 사용자 컴퓨터의 브라우저 메모리 샌드박스 내부로 로드됩니다.
- 캔버스 전처리: 더 정밀한 인식을 위해 오프라인 캔버스에서 이미지 대비와 선명도를 최적화합니다.
- 로컬 해독: 로컬로 로드된 자바스크립트 기반 OCR 엔진이 컴퓨터 자체 프로세서를 사용하여 픽셀을 한 땀 한 땀 분석한 후 한글과 영어를 파싱합니다.
- 즉시 복사: 변환된 텍스트가 화면에 즉시 반환되며, 클릭 한 번으로 복사할 수 있습니다.
이 모든 과정에서 단 1바이트의 파일 데이터도 인터넷 외부로 나가지 않습니다. 페이지를 띄운 직후 와이파이를 끄거나 랜선을 뽑아도 추출 작업은 아무 문제 없이 끝납니다.
기술적 설계: 브라우저 내부의 Tesseract.js
기기 내부에서 구동되는 OCR은 오픈소스 tesseract 엔진을 웹 환경에 맞춰 컴파일한 tesseract.js 라이브러리를 기반으로 합니다. 텍스트 추출 작업 중 브라우저 화면이 멈추는 것을 방지하기 위해 백그라운드 웹 워커 스레드로 돌아갑니다.
엔진이 처음 실행될 때 필요한 언어 모델 학습 파일(traineddata)을 사용자 브라우저의 IndexedDB 저장소에 안전하게 로드합니다. 한 번 캐시된 뒤에는 추가 다운로드 없이 캐시에서 직접 불러와 즉시 실행됩니다.
특히 한글과 영어가 혼용된 업무 문서가 많다는 점에 착안해 두 언어를 UI 설정 변경 없이 한 번에 자동 판독하도록 통합 구성했습니다.
사진 글자를 안전하게 추출하는 구체적 방법
외부 유출 걱정 없이 스크린샷과 사진 속 글자를 로컬에서 긁어오는 구체적인 사용법은 다음과 같습니다.
- 도구 페이지 열기: 브라우저에서 Image to Text 도구로 이동합니다.
- 이미지 파일 열기: 변환할 JPG, PNG, WebP 이미지 파일을 드래그하여 올려놓습니다.
- 로컬 처리 대기: 진행 상태 표시줄을 확인합니다. 외부 서버와 통신하지 않고 본인 컴퓨터 안에서 픽셀 전처리와 해독 작업이 순차적으로 진행됩니다.
- 텍스트 복사 및 저장: 텍스트 상자에 해독 완료된 글자가 나타나면 바로 클립보드에 복사하거나 깔끔한
.txt파일로 다운로드합니다. - 오타 체크: 해독(OCR)은 확률 기반 연산이므로, 촬영 상태가 흐리거나 서명이 겹쳐 있으면 미세한 오타가 생길 수 있습니다. 최종 텍스트를 문서나 이메일에 붙여넣기 전에 직접 확인하는 것이 현명합니다.
브라우저 내 로컬 변환 모델이 기존 클라우드 서버와 비교했을 때 어떻게 안전하고 편리한지 자세한 성능 비교는 비교 페이지에서 볼 수 있으며, 동일한 로컬 엔진이 스캔본 PDF까지 어떻게 처리하는지는 스캔 PDF 텍스트 추출 가이드에서 확인해 보세요.
PDFTasker
Image to Text